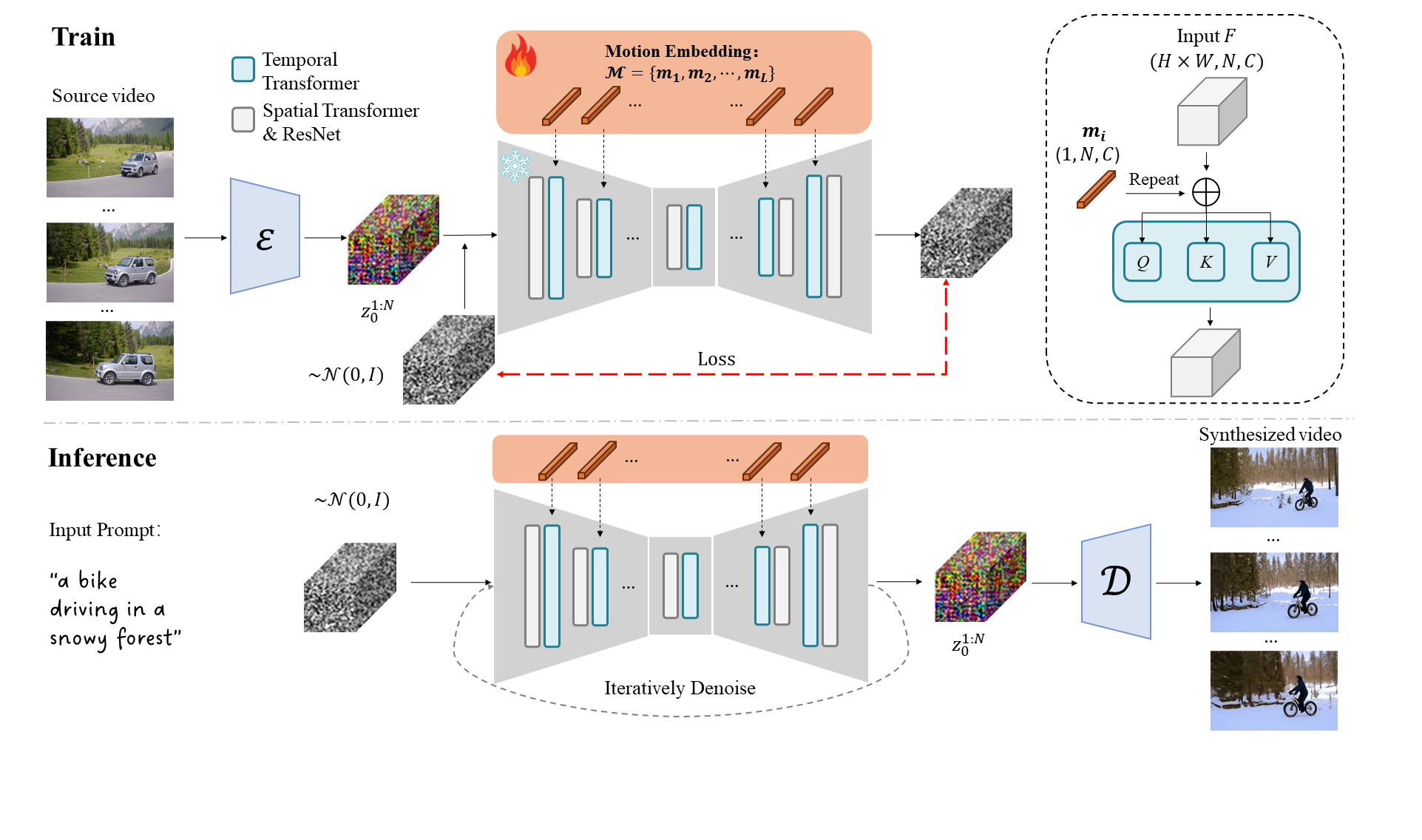
Motion Embeddings
In this research, we propose Motion Embeddings, a set of temporally coherent embeddings derived from a given video. Our approach provides a compact and efficient solution to motion representation, utilizing two types of embeddings: a Motion Query-Key Embedding to modulate the temporal attention map and a Motion Value Embedding to modulate the attention values