
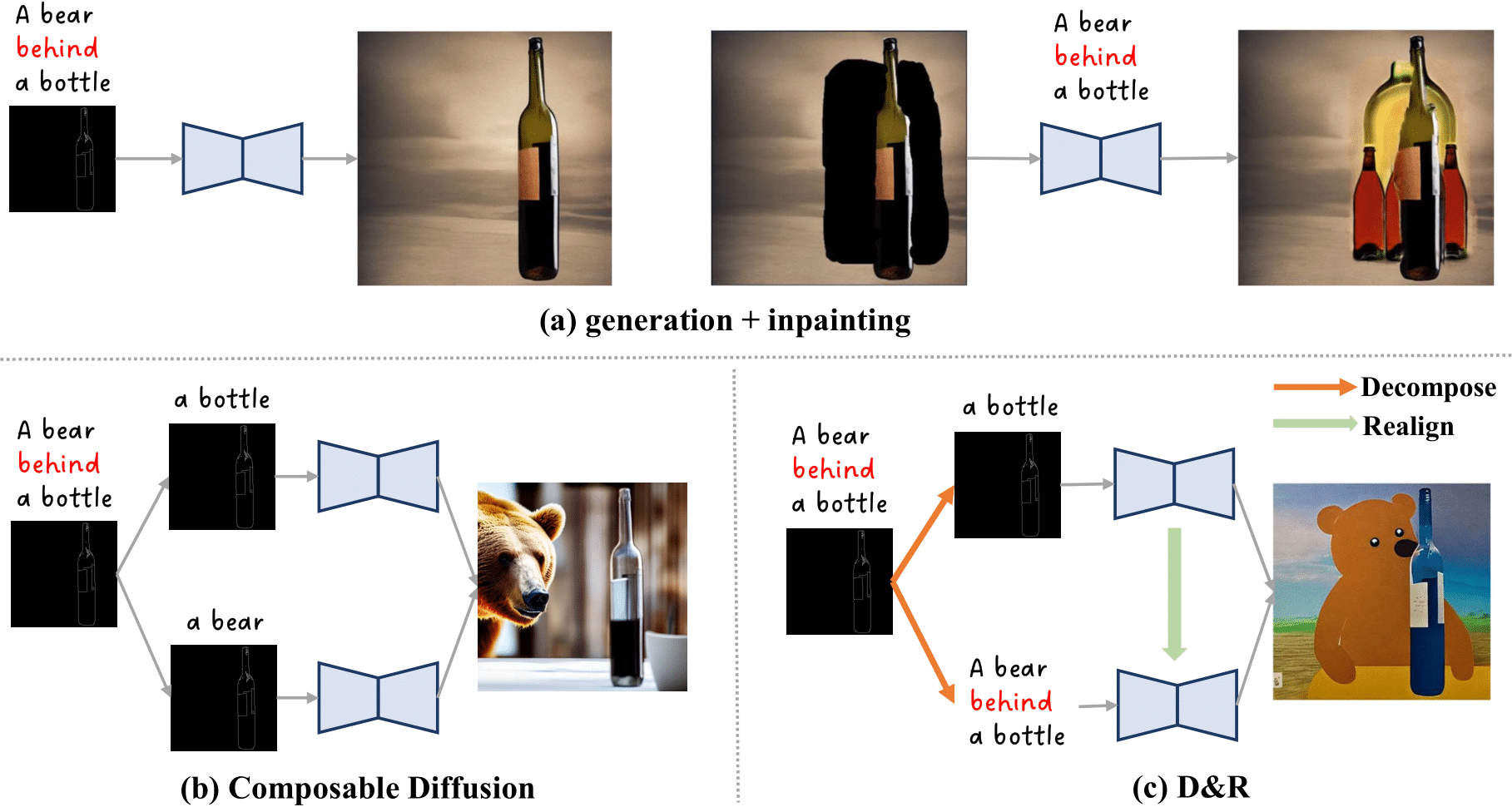
Text-to-image diffusion models have advanced towards more controllable generation via supporting various additional conditions (e.g., depth map, bounding box) beyond text. However, these models are learned based on the premise of perfect alignment between the text and extra conditions. If this alignment is not satisfied, the final output could be either dominated by one condition, or ambiguity may arise, failing to meet user expectations. To address this issue, we present a training-free approach called ``Decompose and Realign'' to further improve the controllability of existing models when provided with partially aligned conditions. The "Decompose" phase separates conditions based on pair relationships, computing the result individually for each pair. This ensures that each pair no longer has conflicting conditions. The "Realign" phase aligns these independently calculated results via a cross-attention mechanism to avoid new conflicts when combining them back. Both qualitative and quantitative results demonstrate the effectiveness of our approach in handling unaligned conditions, which performs favorably against recent methods and more importantly adds flexibility to the controllable image generation process.


@misc{wang2023decompose,
title={Decompose and Realign: Tackling Condition Misalignment in Text-to-Image Diffusion Models},
author={Luozhou Wang and Guibao Shen and Wenhang Ge and Guangyong Chen and Yijun Li and Ying-cong Chen},
year={2023},
eprint={2306.14408},
archivePrefix={arXiv},
primaryClass={cs.CV}
}